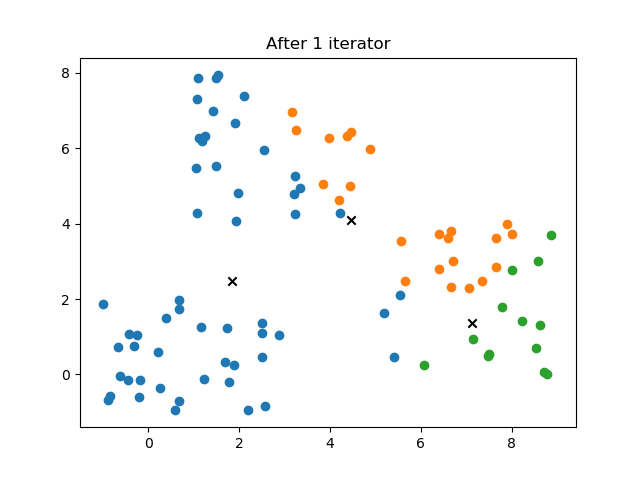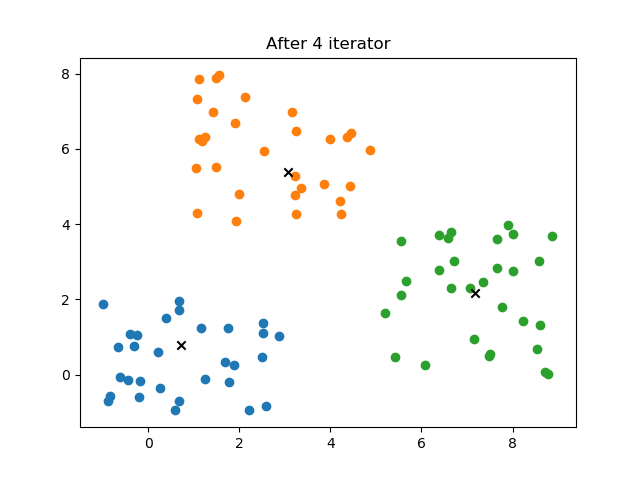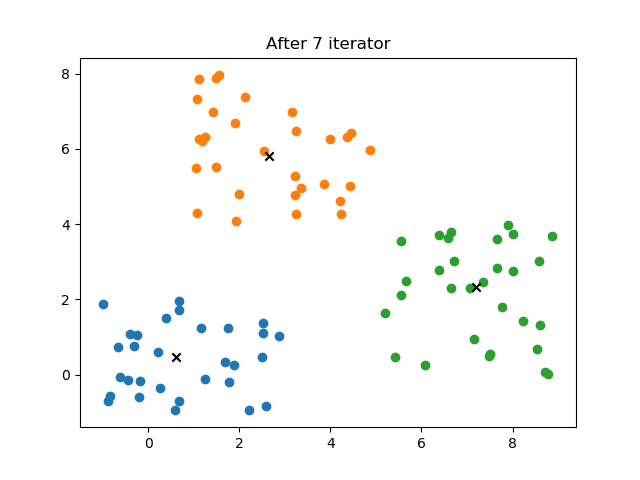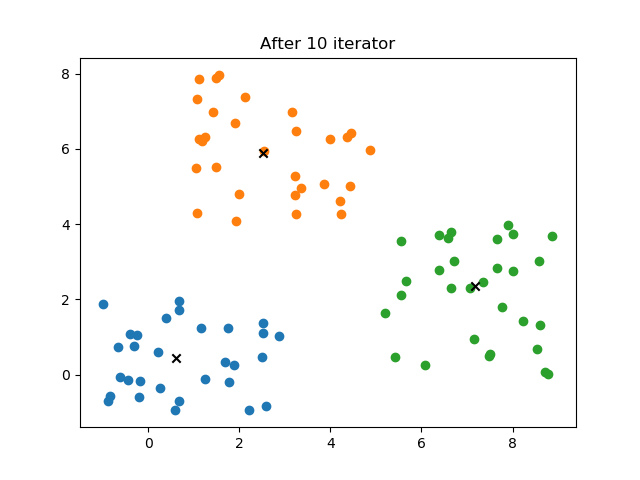
模糊C聚类(Fuzzy C-means Clustering, FCM)
1. 思想
- 簇内距离尽量小(*)
- 簇间距离尽量大
2. 说明
某种程度上类似于 LDA 的思想,但他们间有明显差距,LDA是属于监督学习下的降维操作,而该聚类基于非监督;
过程跟k-means聚类类似,区别在于FCM计算了(中心)点到所有数据点的距离,增加了隶属于某一簇的概率值(隶属值),还有属于某一簇的重视程度 m (\(\gt 1\))
3. 推导
3.1 初始条件
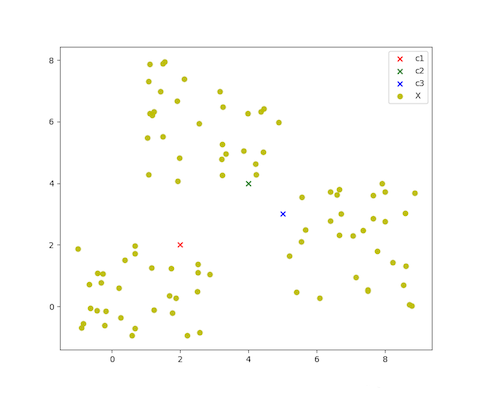
假设有N个原始数据点 \(X = (x_1, x_2, \cdots, x_N)\) ,设定有 L 个簇,初始簇心手动设定为 \(C=(c_1, c_2, \cdots, c_l)\) .
示意图如下(L=3时)
3.2 目标函数
计算每个数据点到簇心的距离(以到第一个簇心\(c_1\)为例)
为了表征一点到不同簇心的隶属程度,设定这些点到某一簇心的概率(隶属值,Membership values)为 \(u_{ki}\),该值表示第 i 点到第 k 个簇心的隶属值。点与簇心距离越大,该值越小。对于同一点来说,有
即,同一点到所有簇心隶属值和为 1
同时为了表示该点实实在在属于某一类,如图中右侧数据的某点属于 蓝色x 的重要程度更高,引入另一个参数:模糊系数(Fuzzifier) m
关于引入了隶属值\(u_{ki}\) 后为什么还要引入模糊系数m?
那么加权后,每个数据点到簇心 \(c_1\) 的距离和为
对于所有点到所有簇心距离和为
该方程就是目标函数,优化方法是最小化该函数
- 若 \(c_k\) 给定时,\(||x_i-c_k||^2\) 为定值(假设为 \(d_{ki}\)),因此也即是最小化
\(Min\ \ J(u_{ki}) = \sum\limits_{k=1}^L\sum\limits_{i=1}^N u_{ki}^m > d_{ki}\)
此时只与\(u_{ki}\) 相关。
- 若隶属值 \(u_{ki}\) 已知,同样可以得到
\(Min\ \ J(c_k) = \sum\limits_{k=1}^L \sum\limits_{i=1}^N u_{ki}^m||x_i-c_k||^2\)
此时只与 \(c_k\) 相关。
3.3 最优化求解
推导过程
对于方程(1*)构造拉格朗日函数
极小值求解 (展开求导)
- 对 \(u_{ki}\)
- 对 \(\lambda_i\)
联立(*1)和(*2),消去\(\lambda_i\)
- 对 \(c_k\)
分析理解
主要得到两个方程(*3)和(*4),为方便理解,先不考虑模糊值 m ,此时有
对于(2*),\(u_{ki}\) 表示第 i 点隶属于 k 簇的概率值,且点到 k 簇的距离越大,该值越小,反之,越大,呈现负相关关系。而点到簇的距离为 \(||x_i - c_k||^2\) ,为了表示上述的负相关关系,可以使用该值的倒数,即 \(\frac{1}{||x_i-c_k||^2}\) ,而为了保证点到所有簇隶属值 u 的和为 1 ,分母除以该点到所有簇的总和,也即
同理,\(c_k\) 表示簇中心,(3*)可类比于质心求解公式。
3.4 问题解决
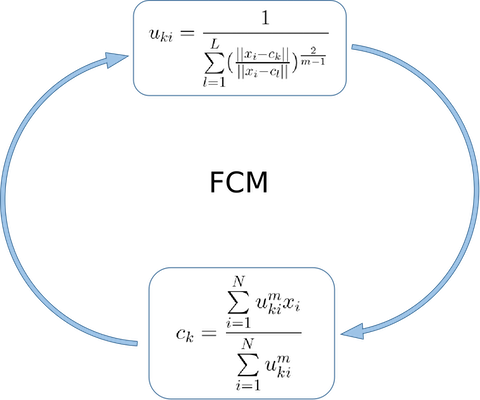
因此,对于上述问题,有两个步骤
- 在 \(c_k\) 给定情况下,可求解出 \(u_{ki}\)
- 在 \(u_{ki}\) 给定情况下,可求解出 \(c_k\)
这是一个循环过程,类比于 k-means 。用图示表示为
4. 实现
4.1 代码
import numpy as np
import matplotlib.pyplot as plt
import imageio
class FCM:
def __init__(self, data, m, c):
self.data = data # 原始数据
self.c = c # 起始簇
self.it = 0 # 迭代次数
self.m = m # 模糊值
self.N = len(self.data) # 原始数据个数
self.L = len(self.c) # 簇数
self.n = len(self.data[0]) # 数据维度
self.U = np.zeros((self.N, self.L)) # 隶属值
self.clusterIni(0)
def clusterIni(self, sig):
self.cluster = {} # 聚类
for i in range(self.L):
if i==0 and sig==0:
self.cluster[i] = data
else:
self.cluster[i] = []
def getU(self):
# 计算u矩阵
for _i,i in enumerate(self.data):
for _k,k in enumerate(self.c):
d = 0
for n in range(self.n):
d = d + (i[n]-k[n])**2
self.U[_i,_k] = np.power(1/d, 1/(self.m-1))
# 标记原始数据点隶属的簇类
cluster = []
for _u,u in enumerate(self.U):
s = np.sum(u)
for _l in range(self.L):
self.U[_u,_l] = self.U[_u,_l]/s
cluster.append(np.argmax(u))
# 记录簇数据
self.clusterIni(1)
for ind,dat in enumerate(self.data):
self.cluster[cluster[ind]].append(dat)
def getC(self):
# 重新计算簇心c
c = []
for l in range(self.L):
s1 = []
for n in range(self.n):
s1.append(0)
s2 = 0
for _i,i in enumerate(self.data):
u = self.U[_i,l]
for n in range(self.n):
s1[n] = s1[n] + np.power(u, self.m) * i[n]
s2 = s2 + np.power(u, self.m)
l = []
for n in range(self.n):
l.append(s1[n]/s2)
c.append(l)
# 判断是否已经收敛
if self.c == c:
return 0
else:
self.c = c
return 1
# 迭代
def iter(self, it):
for i in range(it):
self.getU()
b = self.getC()
self.it = self.it + 1
self.plot(1)
if not b:
print("总共迭代%d次"%(self.it-1))
break
def plot(self, isSave = 0):
# 显示簇
for c in self.cluster:
if(self.cluster[c] == []):
continue
x = np.array(self.cluster[c])[:,0]
y = np.array(self.cluster[c])[:,1]
plt.scatter(x, y)
# 显示中心点
mx = np.array(self.c)[:,0]
my = np.array(self.c)[:,1]
plt.scatter(mx, my, marker='x', color='black')
plt.title("After %d iterator"%self.it)
if isSave:
plt.savefig("./FCM/%d.png"%self.it)
plt.show()
if __name__ == '__main__':
# 原始数据
f = open('./clusterData.txt', 'r')
data = []
for _d in f:
dat = _d.rstrip().split(' ')
data.append([float(dat[0]), float(dat[1])])
f.close()
c = [[3,3],[6,5],[10,1]]
# FCM
obj = FCM(data, 3, c)
obj.iter(10)
# 可视化
inp = []
for i in range(obj.it):
inp.append(imageio.imread('./FCM/%d.png'%(i+1)))
outp = './FCM/fcm.gif'
imageio.mimsave(outp, inp, duration=1)
4.2 结果