前言:本文详尽介绍 SVD、LDA、PCA等算法的基本原理和推导过程,以及简单实例的代码实现。补充了所需要的线性代数基础内容。仍旧有些坑待填。
特征抽取与数据降维(LDA,SVD,PCA)
线性判别分析(Linear Discriminate Analysis, LDA)
奇异值分解(Singular Value Decåomposition, SVD)
主成分分析(Principal Component Analysis, PCA)
因子分析(FA)、独立成分分析(ICA)
1. 线性代数基础
1.1 正交矩阵 /幺正矩阵
如果 n 阶矩阵 A 满足
那么称 A 为正交矩阵,简称正交阵。
如果 A 中元素为复数的话,叫酋矩阵,或幺正矩阵,正交矩阵是幺正矩阵的特例。
1.2 相似矩阵
设A 、B 都是 n 阶矩阵,若有可逆矩阵 P ,使
则称 B 是 A 的相似矩阵,或说 A 与 B 相似。相似矩阵的特征值相同。
矩阵对角化:\(P^{-1}AP=\Lambda=diag(\lambda_1,\lambda_2,...,\lambda_n)\)
1.3 对称矩阵/埃尔米特矩阵
- 若对称矩阵的特征值互不相等,则对应的特征向量互相正交
- 对于n 阶对称矩阵 A ,必存在正交阵 P ,使 \(P^{-1}AP=P^TAP=\Lambda\)
实对称矩阵推广到复数域就是埃尔米特矩阵 (Hermitian Matrix)
具体定义为:埃尔米特矩阵中每一个第i 行第j 列的元素都与第j 行第i 列的元素的共轭相等。
表示为 \(A^H=A\)
1.4 基变换与坐标变换
设 \(\alpha_1,\alpha_2,...,\alpha_n\) 及 \(\beta_1,\beta_2,...,\beta_n\) 是线性空间 \(V_n\) 中的两个基,有
或者
那么,矩阵 P 称为由基 \(\alpha_1,\alpha_2,...,\alpha_n\) 到 \(\beta_1,\beta_2,...,\beta_n\) 的过渡矩阵。 若线性空间一个元素 a,在基 \(\alpha_1,\alpha_2,\cdots,\alpha_n\) 下坐标为 \((x_1,x_2,\cdots,x_n)^T\) ,在基 \(\beta_1,\beta_2,...,\beta_n\) 下坐标为 \((x'_1,x'_2,\cdots,x'_n)^T\) ,若两基满足关系式(2),则有坐标变换公式
更一般情况,我们知道基 \(\alpha_1,\alpha_2,\cdots,\alpha_n\) (且通常 \(\alpha_i=(0,0,\cdots,1,\cdots0,0)\))和其下的坐标表示 \((x_1,x_2,\cdots,x_n)^T\) ,求在基 \(\beta_1,\beta_2,...,\beta_n\) 下的坐标表示
举例说明 (start) ↓
二维坐标点 a 在基 \(\alpha_1=(1,0)^T, \alpha_2=(0,1)^T\) 下坐标为 \((1,1)^T\),则在基 \(\beta_1=(\frac{\sqrt2}{2},\frac{\sqrt2}{2})^T,\beta_2=(-\frac{\sqrt2}{2},\frac{\sqrt2}{2})^T\) 下坐标为 \(a'(x_1',x_2')\)
首先,根据式(2)
则
图示:
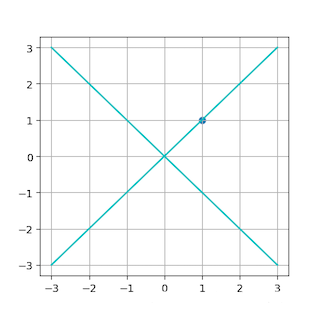
(end)↑
1.5 投影矩阵
若使用 \(A=(\alpha_1,\alpha_2,\cdots,\alpha_m)\) 表示投影面(一个线性子空间或其平移),那么到该面的投影矩阵可表示为
证明如下:
在 \(C^n\) 的线性空间中,求解 b 在 \(A=(\alpha_1,\alpha_2,\cdots,\alpha_m)\) 的投影 p
首先,p 可以由 A 表示 \(p = A\hat x\)
举例说明(start) ↓
在三维坐标系中有两点 \((1,1,0)^T\) \((5,5,4)^T\) ,将由两点组成的向量 b= \((4,4,4)^T\) 投影到 xy 平面得到 p
首先,投影平面 xy 可以由两个线性无关的两个向量 \(\alpha_1,\alpha_2\) 表示
\(\alpha_1 = (1,0,0)^T\) , \(\alpha_2 = (0,1,0)^T\) ,则
投影矩阵 P
则投影得到的 p 为
图示:
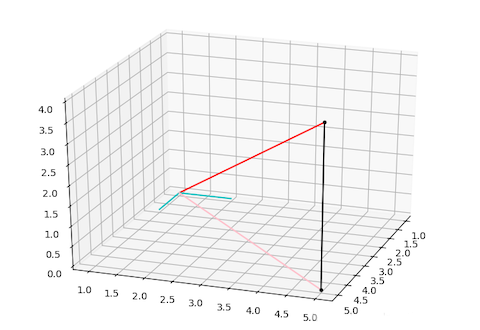
(end)↑
投影矩阵的性质:
投影其实是跟基变换和坐标变换是等价、共通的。\(W\) 与 P 也是等价的,不同之处在于,P 是更体现了降维度的一面,即将数据拍扁在了映射坐标系上,具体途径是设置其余未参与的轴的基坐标为 \((0,0,\cdots,0)\) ,W 则是全维度的坐标变换。所以基于将维问题所说的投影跟坐标变换是等价的。
1.6 协方差矩阵
方差用来度量单个随机变量的离散程度。总体方差定义为
基于无偏估计,样本方差定义为
协方差用来刻画两个随机变量的相似程度,定义为
注意前面系数 \(\frac{1}{n-1}\) 由于是常数,在分析时,直接用作了 \(\frac{1}{n}\) ,不影响结果。
而且,去掉前面的系数项
称其为散度。
方差可以视为随机变量关于自身的协方差
给定 \(l\) 个随机变量 \(x_1,x_2,...,x_l\) ,一共 \(m\) 个观测样本,若用 \(x_{ki}\) 表示第 \(k\) 个观测样本中随机变量 \(x_i\) 的值。
可以用矩阵表示(m行代表第m个样本数据,n列表示第n个随机变量)
则任意两个随机变量 \(x_i,x_j\) 间的协方差为
一般可以通过数据的预处理,使得随机变量样本均值 \(\bar x_i=0\)
此时有
其实此时,求和项就是 \(X^TX\) 的第 i 行 j 列 元素,后面的协方差矩阵就可以用 \(X^TX\) 来表示。
举例说明(start)↓
| 样本编号 | 年龄 \(x_1\) | 身高 \(x_2 \) | 体重 \(x_3\) |
|---|---|---|---|
| 1 | 20 | 181 | 75 |
| 2 | 40 | 177 | 60 |
| 3 | 15 | 156 | 46 |
| 4 | 33 | 170 | 57 |
可以写成矩阵形式
则两个变量协方差为
其余任意两个变量间求解类似。
(end)↑
定义协方差矩阵为
如果经过了上述的均值预处理,就有
很明显,协方差矩阵是对称矩阵。
值得注意的一点是
也就是协方差矩阵的对角和等于各个随机变量的方差和。
(说明:一般情况,在用X矩阵表示数据时,一般是每个样本的数据作为列向量,也就是上述 X 的转置,下面就按照常规写法书写,上述不再更正)
1.7 矩阵求导
(挖坑:推导过程参考矩阵论相关)
1.8 瑞利熵
瑞利熵
若 x 为非零向量,A 为 n 阶 Hermitian 矩阵,则
称作瑞利熵(Rayleigh quotient)。
两条很重要的性质:
- R(A, x) 最大值为矩阵 A 最大特征值
- R(A, x) 最小值为矩阵 A 最小特征值
即 \(\lambda_{min} \leq R(A,x)\leq\lambda_{max}\)
证明:
实际问题中,一般 A 是给定的。对 x 放大缩小不影响其结果,转化为最优化问题(以最大化为例) $$ max\ x^HAx \s.t. \ \ x^Hx=const $$ 利用拉格朗日乘子法,构造拉格朗日函数 $$ f(x,\lambda) = x^HAx- \lambda(x^Hx - c) $$ 求极值 $$ \frac{\partial f(x,\lambda)}{\partial x} = 0 \Rightarrow 2Ax - 2\lambda x = 0 \Rightarrow Ax=\lambda x $$
带入到最优化问题中 $$ max\ x^HAx \Rightarrow max\ \lambda x^H x \Rightarrow max\ c\lambda $$ 如果考虑瑞利熵的分母,则 \(max\ \frac{x^Hx}{x^Hx}=max\ \lambda\) 。可以看出,瑞利熵的最值问题就是求解 \(\lambda\) 的最值问题,且 \(\lambda\) 为 A 的特征值,x 为其对应的特征向量。
说明:PCA 推导得到的最优化问题就是 瑞利熵问题。
额外可参考:瑞利商与极值计算
广义瑞利熵
若 x 为非零向量,A,B为 n 阶 Hermitian 矩阵,则
称为广义瑞利熵(generalized Rayleigh quotient)
想法将广义情况想一般瑞利熵转化,即将分母转化为 \(x'^Hx'\) 形式,也即消掉 B,找到 \(x‘\) 与 \(x\) 的关系。
则对于分母
令
则
广义瑞利熵转换为
这就是一般瑞利熵问题,有
- R(A, B, x) 最大值为矩阵 \(B^{-\frac{1}{2}}AB^{- \frac{1}{2}}\) 最大特征值
- R(A, B, x) 最小值为矩阵 \(B^{-\frac{1}{2}}AB^{- \frac{1}{2}}\) 最小特征值
注意:\(B^{- \frac{1}{2}}AB^{- \frac{1}{2}} = B^{-1}A\)
说明:LDA 推导得到的最优化问题就是 广义瑞利熵问题。
2. 奇异值分解(Singular Value Decomposition, SVD)
2.1 正交对角分解
设 A \(\in R^{n\times n}\) 可逆,则存在正交矩阵 P 和 Q ,使得
证明: 因为A可逆,则 \(A^TA\) 为实对称正定矩阵,则存在正交矩阵 Q,使
\(Q^T(A^TA)Q=diag(\lambda_1,\lambda_2,\cdots,\lambda_n)\)
其中,\(\lambda_i>0\) 为 \(A^TA\) 的特征值,且令 \(\sigma_i = \sqrt \lambda_i,\ \ \Lambda=diag(\lambda_1,\lambda_2,\cdots,\lambda_n)\)
可以得到
\((AQ\Lambda^{-1})^T(AQ)=\Lambda\)
令 \(P=AQ\Lambda^{-1}\) ,很容易得到 $$ P^TP=E $$ 即 P 为正交矩阵
得证。
矩阵 A 的正交对角分解可表示为
其中,P, Q 均为正交矩阵,\(\lambda_i\) 为 \(A^TA\) 的特征值。
2.2 奇异值分解
设 A \(\in C_R^{m\times n}\) ,\(A^TA\) 的特征值为
称 \(\sigma_i=\sqrt \lambda_i\) 为矩阵 A 的奇异值。
A 存在 m 阶酋矩阵 U 和 n 阶酋矩阵 V ,使得
或者写作
其中
称 (*)为矩阵 A 的奇异值分解。证明过程与正交分解有类似之处,省略。
- 求解
对于任意矩阵 A,
即:对
求特征值和特征向量,得到特征向量矩阵 U(列),特征值矩阵 \(\Sigma^2\)
即:对
求特征值和特征向量,得到特征向量矩阵 V(列),特征值矩阵 \(\Sigma^2\)
实例 $$ A=\left[ \begin{matrix} 1&0&1\ 0&1&1\ 0&0&0 \end{matrix} \right] $$ 对矩阵 A 进行 SVD 分解。
编程实现
import matplotlib.pyplot as plt
import numpy as np
a = np.array([[1,0,1],[0,1,1],[0,0,0]])
b = np.dot(a.T,a) # a.T*a
c = np.dot(a,a.T) # a*a.T
b1 = np.linalg.eig(b)
c1 = np.linalg.eig(c)
sigma1 = np.sqrt(c1[0][0])
sigma2 = np.sqrt(c1[0][1])
sigma3 = np.sqrt(c1[0][2])
Sigma = np.diag([sigma1,sigma2,sigma3])
V = b1[1]
U = c1[1]
U[:,1] = -U[:,1]
V = -V
print("sigma_u = ", np.sqrt(c1[0]))
print("sigma_v = ", np.sqrt(b1[0]))
print("U=", U)
print("V=", V)
A = np.dot(np.dot(U,Sigma),V.T)
print("a=", a)
print("A=", A)
# 使用python自带的svd
u,s,v = np.linalg.svd(a)
print("u = ", u, "\ns = ", s, "\nv = ", v)
- result :
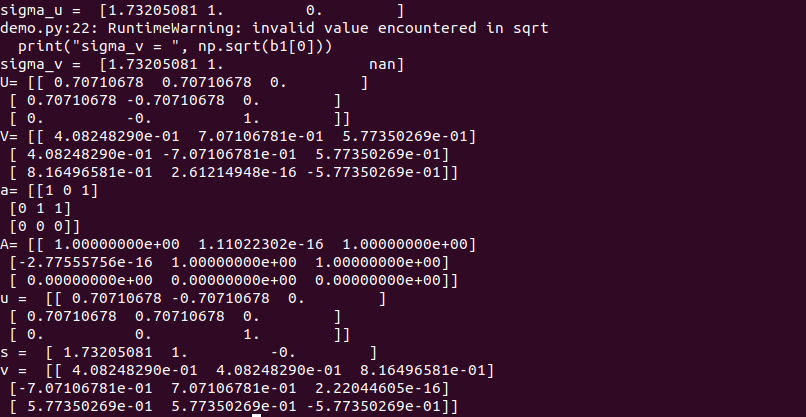
注意事项:
- U,V 不唯一
- 自编程时注意U,V两个特征值可能不是按照同一顺序排列,特征向量也存在正负号的问题
- 由于特征向量正负号的原因,在进行验证时,尤其要注意,往往直接求解得到的 \(USV^T \neq A\)
参考:
《矩阵论》
3. 主成分分析(Principal Component Analysis, PCA)
3.1 总体概括
- 基于方差,PCA 轴正交
- 无监督(不需要标签)
- 优点:降低数据复杂度,识别最重要的多个特征,可以降低到任意维度
- 缺点:可能损失掉有用信息
3.2 问题引入
假设有如下 4随机变量,6个样本数据(数据比较极端,但能很好说明 PCA 的思想),通过这四个变量预测某件事y.
| 样本编号 | \(x_1\) | \(x_2\) | \(x_3\) | \(x_4\) |
|---|---|---|---|---|
| 1 | 10 | 0 | 10 | -10 |
| 2 | 23 | 0 | 10 | -23 |
| 3 | 76 | 0 | 10 | -76 |
| 4 | 13 | 0 | 10 | -13 |
| 5 | 19 | 0 | 10 | -19 |
| 6 | 99 | 0 | 10 | -9 |
事实上,很容易可以看出来,这么多随机变量,其实只有一个是有贡献的。
对于随机变量 \(x_2,x_3\) 来讲,对预测不起作用,对于 \(x_1,x_4\) ,两者其实是协同的。
那么如何过滤掉 \(x_2,x_3\) 这种数据呢,基本想法是考察其方差。如何表现 \(x_1,x_4\) 的这种协同关系呢,可以通过线性组合变换对这种数据进行考察。
什么是 PCA ?
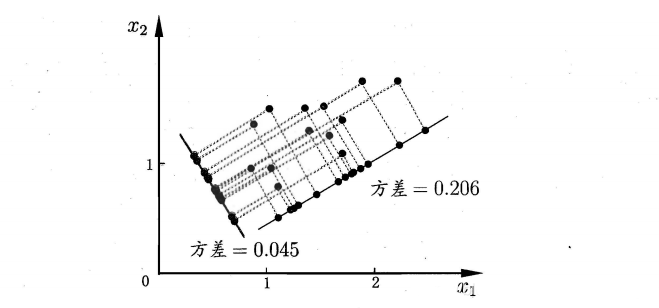 对原始数据进行坐标转换,找到指定维度中最能够表征数据信息的 PCA 轴,来用此表征原始数据,达到降维的目的。
对原始数据进行坐标转换,找到指定维度中最能够表征数据信息的 PCA 轴,来用此表征原始数据,达到降维的目的。
3.3 推导过程
3.3.1 条件
给定 \(l\) 个随机变量 \(x_1,x_2,...,x_l\) ,一共 \(m\) 个观测样本,若用 \(x_{ik}\) 表示第 \(k\) 个观测样本中第 i 个随机变量的值
用矩阵表示即为 (这里不同于前面表示,这种是常规表示,列向量为每个样本中的数据,行向量为同一随机变量在不同样本中的数据)
这里,一般会对样本进行中心化处理,也即 \(\mu_i=0\)
投影变换坐标系 \(W = (w_1,w_2,\cdots,w_l)\) ,由标准正交基向量组成。
变换后的坐标为
3.3.2. 思路
- 基于最近重构性:所有样本点距离投影超平面距离和最近
- 基于最大可分性:所有样本点投影后尽可能分开
(1) 基于最近重构性
求解原始点与投影超平面距离和,然后最小化即可。
根据(4-3)我们知道,新坐标系 W 下,样本点坐标为 \(W^{-1}X\) 因为 W 是单位正交基,\(W^{-1}=W^T\) ,新坐标下样本点坐标为 \(W^TX\) ,如上所示。
第 k 个样本点坐标为 \(W^Tx_k\) ,第 k 个样本点第 i 个随机变量(维度)在新坐标系下值为 \(W^Tx_{ki}\),而该值(的绝对值)其实就是新坐标下第 k 样本点与除去 i 维坐标后的超平面的距离值(记为d‘)。我们要找的是距离包含 i 维的超平面的距离和最小值,相反就是使得上述 d’ 最大化。
关于 d‘ 的求解,就是变换后的坐标的绝对值,为方便,使用平方表示,也即 \(X'\) 中所有元素平方求和
其实不用公式推导,在中心化的条件下,矩阵所有元素平方和相加就是所有方差和,也就是 \(X'\) 协方差矩阵的对角元素和。
(说明:当降低一维的时候这种思路比较容易理解,当降低多个维度时,自己陷入思维困境。正统做法,参考《机器学习》中方法即可,那个比较好理解)
最优化问题
(2) 基于最大可分性
求解在转换后的新坐标系下,样本在各个新轴投影的方差。
根据(4-3)我们知道,新坐标系 W 下,样本点坐标为 \(W^{-1}X\) 因为 W 是单位正交基,\(W^{-1}=W^T\) ,新坐标下样本点坐标为 \(W^TX\) 。
对于一系列随机变量,如何求解在各个轴投影上的方差呢,参考协方差(6-4),我们只需要对其得到协方差矩阵即可。对角线部分即是投影到各个轴上的方差,其余部分因为基正交的原因,协方差都为 0 .
那么由(6-3)求解 \(W^TX\) 的协方差矩阵
最优化问题
上述最优化问题就是瑞利熵最优化问题
3.3.3 方法
- 基于拉格朗日乘子
- 基于奇异值
(1) 基于拉格朗日乘子
构造拉格朗日函数
求极值
带入到最优化问题
问题转化为求解 \(\lambda\) 最大值。且 \(\lambda\) 为协方差矩阵 \(XX^T\) 的特征值,对应的特征向量就是 W。
总结来看,需要做的工作就是:对协方差矩阵进行特征值和特征向量的求解,然后按照特征值从大到小排序,从中选取出前 \(l'\) 个特征值和其对应的特征向量(投影矩阵 \(W’\) )。最终投影后的得到值 \(W'^TX\),就是最后降维的结果。
(2) 基于奇异值
回到式子(*4),该矩阵对角线元素对应着每个变量(维度投影后)的方差
我们目标是求解 W,同时注意到
式(*4)变为
其实我们的目标就是求得变换 W 使原始坐标下的协方差矩阵对角化。对角元素如按照从大到小顺序排列,那么 W 矩阵的前 \(l'\) 列就是我们要寻找的基(变换矩阵)。
对于 W 的求解,不就是奇异值分解的内容嘛。
3.4 算法流程
样本集 \((x_1,x_2,\cdots,x_m)\) 从 \(l\) 维降低到 \(l'\) 维
- 样本中心化处理: \(x_i \leftarrow x_i-\frac{1}{m}\sum\limits_{i=1}^m x_i\)
- 计算样本的协方差(散度)矩阵 \(XX^T\)
- 对协方差矩阵 \(XX^T\) 做特征值分解
- 取最大的 l' 个特征值对应的特征向量 \(w_1,w_2,\cdots,w_{l'}\)
得到投影矩阵 \(W’=(w_1,w_2,\cdots,w_{l'})\) ,样本输出 \(W'^TX\)
3.5 实现
为了可视化方便,使用二维数据,降低到一维,数据集如下
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| \(x_1\) | -4 | -3 | -2 | -1 | 0 | 1 | 2 | 3 | 4 | 5 |
| \(x_2\) | -5 | -4 | -1 | -3 | 0 | 3 | 3 | 4 | 3 | 7 |
3.5.1 基于协方差矩阵的特征值分解
- 求解协方差矩阵 \(XX^T\) 的特征值与特征向量
- 特征值从大到小排序,找到对应的前 l' 个特征向量
这种方法基于协方差矩阵的求解比较耗时
3.5.2 基于协方差矩阵的 SVD 分解
- 对 X 进行 SVD 分解,得到特征值和特征向量矩阵 U
- 特征值从大到小排序,找到 U 中对应的前 l' 个特征向量
3.5.3 代码实现
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
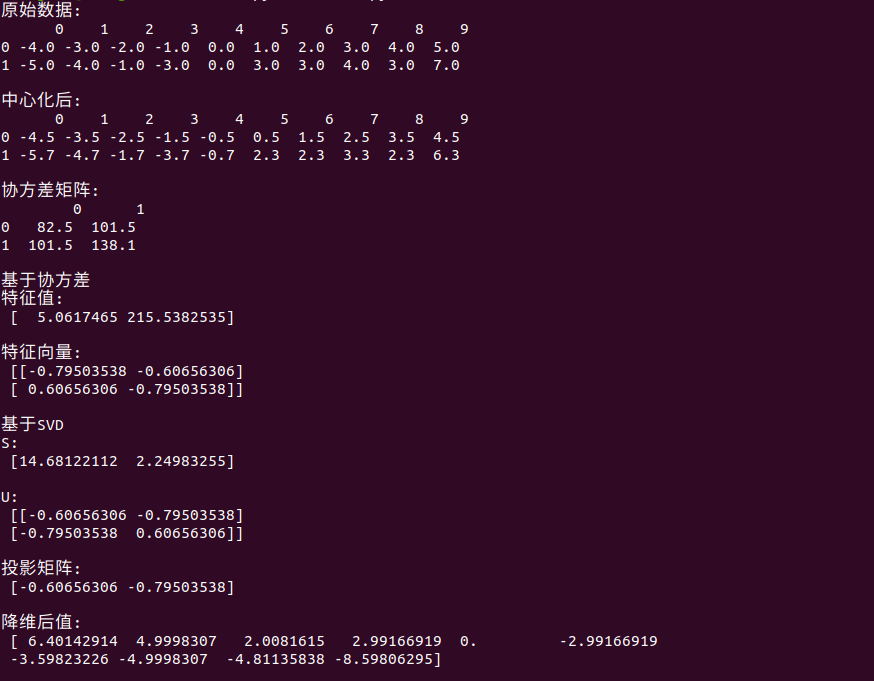
def PCA():
x0 = np.array([[-4,-3,-2,-1,0,1,2,3,4,5],[-5,-4,-1,-3,0,3,3,4,3,7]], dtype=np.float)
x = x0.copy()
data = pd.DataFrame(x)
print("原始数据: \n",data,"\n")
# 中心化
x[0] = x[0] - np.sum(x[0])/len(x[0])
x[1] = x[1] - np.sum(x[1])/len(x[1])
data2 = pd.DataFrame(x)
print("中心化后: \n",data2,"\n")
# 协方差矩阵
Sigma = np.dot(x,x.T)
data3 = pd.DataFrame(Sigma)
print("协方差矩阵: \n",data3,"\n")
# 特征值与特征向量
s = np.linalg.eig(Sigma) # 基于协方差矩阵求解
Lambda = s[0]
print("基于协方差\n特征值: \n", Lambda,"\n")
w = s[1]
print("特征向量: \n",w,"\n")
U,S,v = np.linalg.svd(x) # 基于 SVD 分解求解
print("基于SVD\nS: \n",S,"\n")
print("U: \n",U,"\n")
# 投影矩阵
W = w[:,1]
print("投影矩阵: \n",W,"\n")
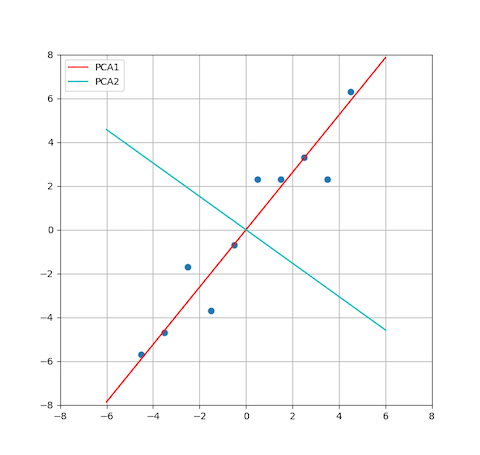
# PCA 轴
xx = np.linspace(-6,6,7)
y1 = W[1]/W[0] * xx
y2 = w[:,0][1]/w[:,0][0] * xx
plt.plot(xx,y1,color="r")
plt.plot(xx,y2,color="c")
plt.legend(["PCA1","PCA2"])
# np.dot(w[:,1],w[:,0].T) = 0 轴是垂直的
# 降维后的值
xx = np.dot(W,x0)
print("降维后值: \n",xx,"\n")
plt.scatter(x[0],x[1])
plt.xlim(-8,8)
plt.ylim(-8,8)
plt.grid()
plt.show()
PCA()
result :
4. 线性判别分析(Linear Discriminate Analysis, LDA)
4.1 基本内容
- LDA 轴不是正交的
- 监督学习
- 不同类投影中心点间距尽量大
- 同类投影间距尽量小
4.2 公式推导
假设有 \(L\) 个类别,数据点表示如下
第一类样本点:\(x_1^{(1)}, x_2^{(1)}, ..., x_k^{(1)}, ..., x_{n_1}^{(1)}\),共 \(n_1\)个数据
第二类样本点:\(x_1^{(2)}, x_2^{(2)}, ..., x_k^{(2)}, ..., x_{n_2}^{(2)}\),共 \(n_2\)个数据
...
第 \(i\) 类样本点:\(x_1^{(i)}, x_2^{(i)}, ..., x_k^{(i)}, ..., x_{n_i}^{(i)}\),共 \(n_i\)个数据
\(e^T\)为投影矩阵,第 \(i\) 类样本点投影后的中心 \(m_i\) 为:
其中,\(\hat m_i = \frac{1}{n_i}\sum\limits_{l=1}^{n_i}x_l^{(i)}\) 表示第 i 类样本(投影前)的中心(或平均值)
4.2.1 不同类间距最大化
那么投影后,任意两类间的中心间距为
其中,\(P_i\)与\(P_j\)表示取到\(i\)或\(j\)类点的概率
所有类投影后中心间距总和为
说明:(I)直接求和累加,每两点计算了两次,所以要除以2 (II)常数的转置仍为本身\(N=N^T\)
类间
为方便理解,假设类别数 \(L=3\)
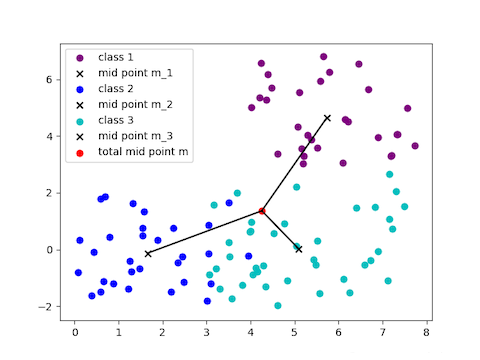
\(S_b^{LDA}\) 表征各类别中心点(图中"x"表示的m_i)之间的距离总和,可以使用每个类别中心点到总体中心点(图中"o"表示的 m)来代替表示,也即
事实上,(1)(2)两者是相等的,证明如下
左侧:
右侧:
得证。
也即:
这称作类间的散度矩阵。(注意:\(P_i\) 为取到该类点的概率)
4.2.2 同类间距最小化
那么投影后同类点到该类投影后中心点\(m_i\)的间距和为
对于所有类别点,同类间距之和为
其中
称作类内的散度矩阵。
4.2.3 Linear Discriminate Analysis
综合以上
| Distances | Scatter Matrix | Analysis | |
|---|---|---|---|
| Between-class | \(D_b = e^T S_b^{LDA} e\) | \(S_b^{LDA} =\sum\limits_{i=1}^L P_i(\hat m_i-\hat m)(\hat m_i -\hat m)^T\) | \(arg max(D_b)\) |
| Within-class | \(D_w = e^T S_w^{LDA} e\) | \(S_w^{LDA}=\sum\limits_{i=1}^L P_i\frac{1}{n_i} \sum\limits_{l=1}^{n_i}(x_l^{(i)}-m_i)(x_l^{(i)}-m_i)^T\) | \(argmin(D_w)\) |
有个很有用的关系: 总体散度 = 类间散度 + 类内散度
同时考虑 \(argmax(D_b)\) 和 \(argmin(D_w)\) ,问题转化
其中
称作为泛化瑞利熵(generalized Rayleigh quotient)
因此,LDA的目标就是最大化广义瑞利熵
参考前述瑞利熵内容,将其转化为一般瑞利熵,有
像极了 PCA 中的最优化问题。
4.3 算法流程
样本集 \((x_1,x_2,\cdots,x_m)\) 从 \(l\) 维降低到 \(l'\) 维
- 计算类内散度矩阵 \(S_w\)
- 计算类间散度矩阵 \(S_b\)
- 计算矩阵 \(S_w^{-1}S_b\) ,对其进行特征值分解
- 取最大的 \(l'\) 个特征值对应的特征向量 \(w_1,w_2,\cdots,w_{l‘}\)
得到投影矩阵 \(W'=(w_1,w_2,\cdots,w_{l'})\),输出结果 \(W'^TX\)
4.4 实现
使用与 PCA 类似的数据,不过添加了标签
Class 1:
| 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|
| \(x_1\) | -4 | -3 | -2 | -1 | 0 |
| \(x_2\) | -5 | -4 | -1 | -3 | 0 |
Class 2:
| 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|
| \(x_1\) | 1 | 2 | 3 | 4 | 5 |
| \(x_2\) | 3 | 3 | 4 | 3 | 7 |
代码如下:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
def LDA():
x1 = np.array([[-4,-3,-2,-1,0],[-5,-4,-1,-3,0]], dtype=np.float)
x2 = np.array([[1,2,3,4,5],[3,3,4,3,7]], dtype=np.float)
l1 = len(x1[0])
l2 = len(x2[0])
l = l1 + l2
p1 = l1/l # 类1概率
p2 = l2/l # 类2概率
m1 = np.array([[np.sum(x1[0,:])/len(x1[0,:])],[np.sum(x1[1,:])/len(x1[1,:])]]) # 类1中心(均值)
m2 = np.array([[np.sum(x2[0,:])/len(x2[0,:])],[np.sum(x2[1,:])/len(x2[1,:])]]) # 类2中心(均值)
m = p1*m1 + p2*m2 # 总体中心(均值)
data1 = pd.DataFrame(x1)
data2 = pd.DataFrame(x2)
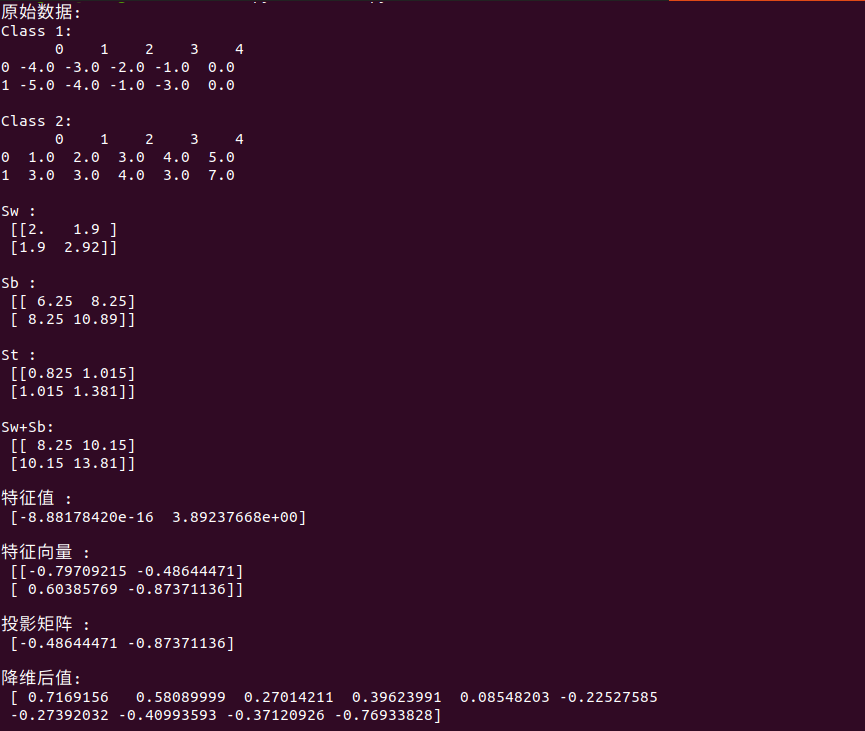
print("原始数据: \nClass 1:\n",data1,"\n")
print("Class 2:\n",data2,"\n")
# 类内散度矩阵
Sw_1 = p1*(1/l1) * np.cov(x1) * (l1-1)
Sw_2 = p2*(1/l2) * np.cov(x2) * (l2-1)
Sw = Sw_1 + Sw_2
print("Sw : \n",Sw,"\n")
# 类间散度矩阵
Sb_1 = p1 * np.dot(m1-m,(m1-m).T)
Sb_2 = p2 * np.dot(m2-m,(m2-m).T)
Sb = Sb_1 + Sb_2
print("Sb : \n",Sb,"\n")
# 总散度矩阵
x0 = np.hstack((x1,x2))
St = 1/l * np.cov(x0) * (l-1)
print("St : \n",St,"\n")
print("Sw+Sb: \n",Sw+Sb,"\n")
# 另一种求法
x0[0] = x0[0] - np.sum(x0[0])/len(x0[0])
x0[1] = x0[1] - np.sum(x0[1])/len(x0[1])
# 特征值与特征向量
S = np.dot(np.linalg.inv(Sw),Sb)
s = np.linalg.eig(S)
Lambda = s[0]
w = s[1]
print("特征值 : \n",Lambda,"\n")
print("特征向量 : \n",w,"\n")
# 投影矩阵
W = w[:,1]
print("投影矩阵 : \n",W,"\n")
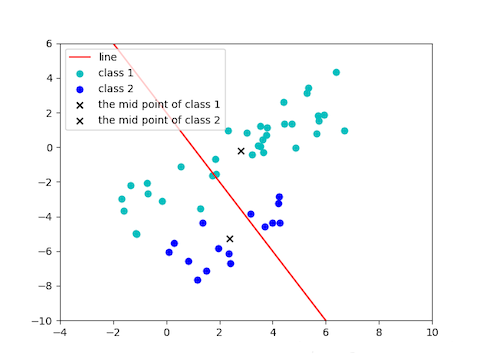
# LDA 轴
xx = np.linspace(-6,6)
y1 = W[1]/W[0] * xx
y2 = w[:,0][1]/w[:,0][0] * xx
plt.plot(xx,y1,color="r")
plt.plot(xx,y2,color="c")
plt.legend(["LDA1","LDA2"])
# np.dot(w[:,1],w[:,0].T) != 0 轴不一定垂直
# 降维后的值
xx = np.dot(W,x0)
print("降维后值: \n",xx,"\n")
plt.scatter(x1[0],x1[1],color="b")
#plt.scatter(m1[0],m1[1],color="b",marker="x")
plt.scatter(x2[0],x2[1],color="r")
#plt.scatter(m2[0],m2[1],color="r",marker="x")
#plt.scatter(m[0],m[1],color="black",marker="x")
plt.xlim(-8,8)
plt.ylim(-8,8)
plt.grid()
plt.show()
LDA()
result:
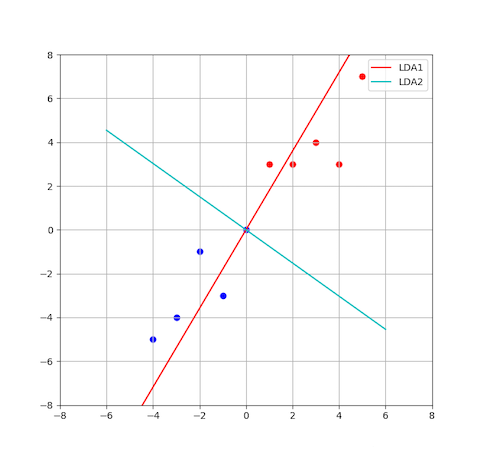
说明:
LDA 的两轴一般不是正交的
对于散度矩阵的求解可以使用代码所示两种方法 $$ \begin{aligned}&(1)\ \ S = cov(X) * (N-1) \&(2)\ 中心化X\ \ \rightarrow\ \ XX^T\end{aligned} $$
5. LDA 与 PCA
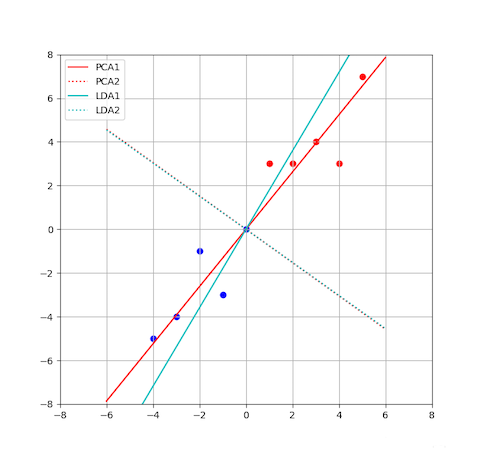
给出上述“相同”实例中,两者的降维结果图:
5.1 共同点
- 都假设数据服从高斯分布
- 都是用于降低维度
- 都使用了特征分解思想
5.2 不同点
- LDA 是广义瑞利熵的应用;PCA 是一般瑞利熵的应用
- LDA 是有监督有标签,所以也可以用于分类;PCA 是无监督
- LDA 思想是类内间距最小,类间间距最大;PCA 思想是投影后方差最大
- LDA 降低到 k-1 维度;PCA 没有限制
- LDA 轴一般是不正交的;PCA 轴正交
- 具体情况,具体分析